14. 람다식
람다식이란?
원래 함수적 프로그래밍 언어에서 쓰이던 개념이다.
병렬 처리와 이벤트 지향 프로그래밍에 적합하다.
자바8부터 지원한다.
익명함수를 생성하기 위한 식으로 객체 지향 언어보다는 함수 지향 언어에 가깝다.
컬렉션 요소의 필터링, 매핑 등 작업을 쉽게 만들어준다.
매개변수를 지닌 코드 블록으로, 런타임 시에 익명 구현 객체를 생성한다.
수학자 Alonzo Church가 발표한 람다 계산법에서 사용된 식으로, John McCarthy가 프로그래밍 언어에 도입했다.
Runnable 을 람다식으로 표현하는 예제
람다식 전
Runnable runnable = new Runnable() {
@Override
public void run() { ... }
}람다식 후
람다식은 익명의 Runnable 객체를 생성한다.
람다식 기본 문법
->기호는 매개변수를 이용해서 중괄호 {}를 실행한다는 뜻으로 해석하면 된다.
기본형
매개변수 축약형 (일반적으로 사용)
일반적으로 타입은 인터페이스의 추상 메소드를 통해 자동으로 인식되기 때문에 언급하지 않는다.
실행문 축약형 (일반적으로 사용)
일반적으로 실행문이 1줄일 때는 실행문을 축약시킨다.
실행문 return 축약형 (일반적으로 사용)
return 할 값에 따로 2줄 이상의 코드가 필요하지 않다면, 위와 같이 작성하면 자동으로 return된다.
타겟 타입과 함수적 인터페이스
람다식은 기본적으로 익명 구현 클래스를 생성하고 객체화한다. 람다식은 대입될 인터페이스의 종류에 따라 작성 방법이 달라지기 때문에 람다식이 대입될 인터페이스를 람다식의 타겟 타입(target type)이라고 한다.
함수적 인터페이스(@FunctionalInterface)
인터페이스 내부에 추상 클래스가 딱 하나만 있어야 람다식으로 구현이 가능하며, 타겟 타입이 될 수 있다.
@FunctionalInterface애노테이션을 붙이면, 두 개 이상의 추상 메소드가 선언되지 않도록 컴파일러가 체킹을 해준다.단, 디폴트 메소드 등은 추가로 있어도 무방하다.
@FunctionalInterface애노테이션은 어디까지나 선택사항이다.
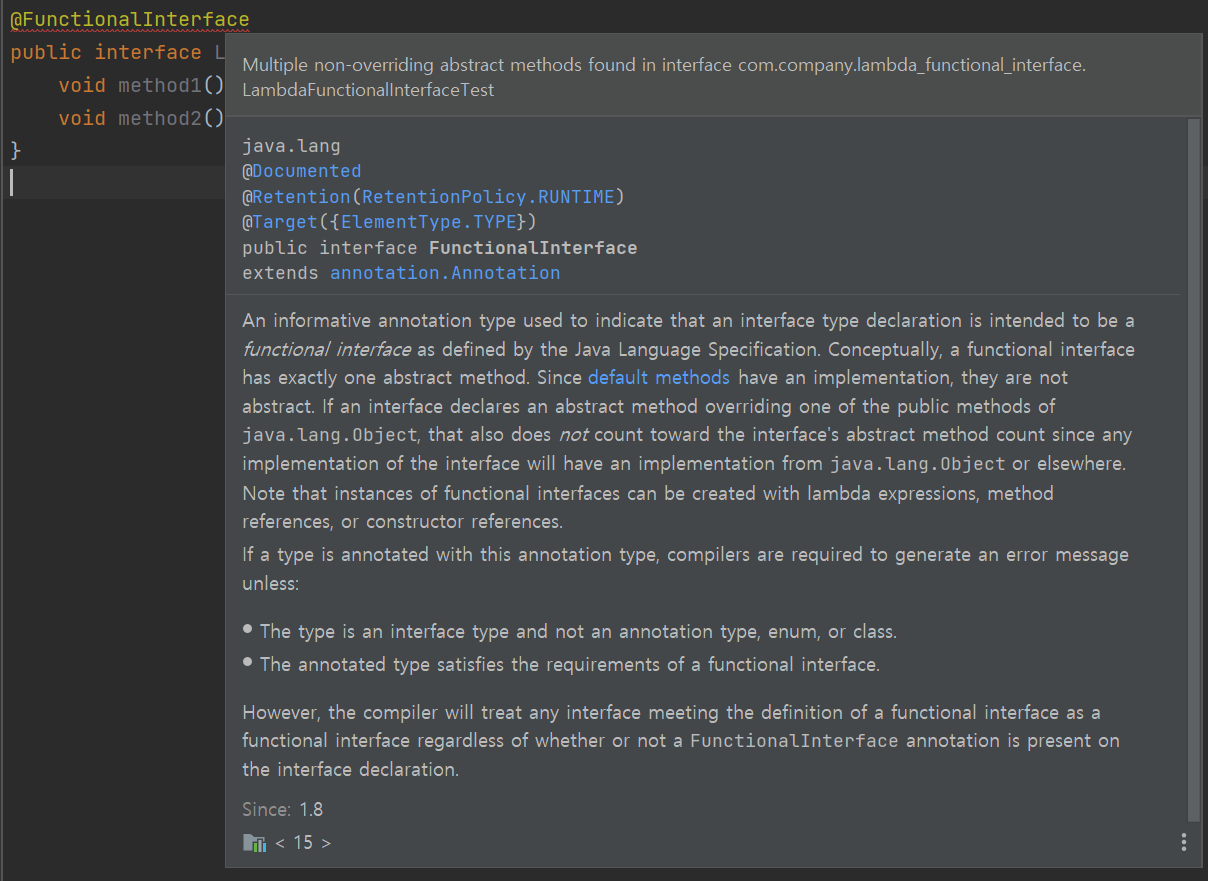
메소드를 2개 이상 만들면 위와 같은 컴파일 에러가 뜬다. 단, 위의 설명을 보면 디폴트 메소드나 Object 타입의 기본 메소드를 오버라이드하는 것은 상관없다고 한다.
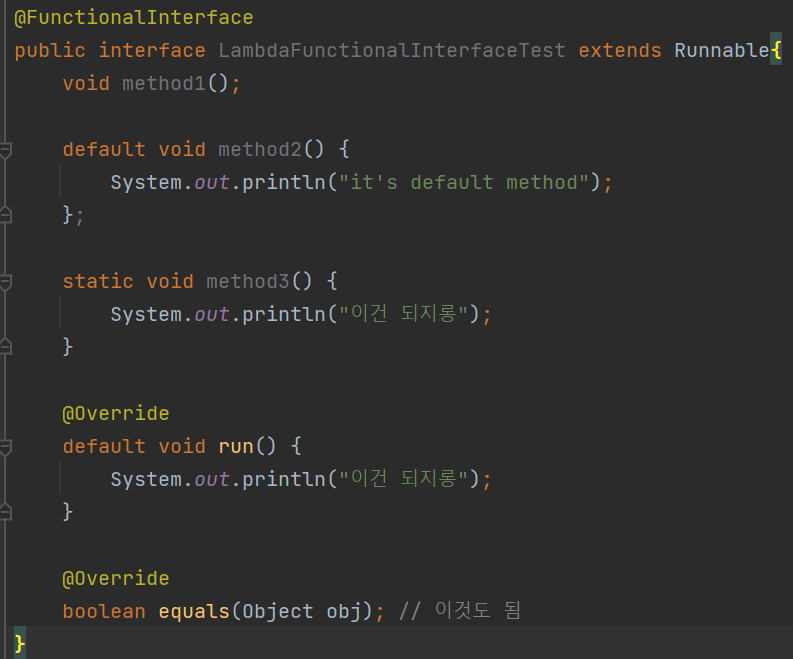
상기 항목들은 상관없다.
디폴트 메소드
정적 메소드
오버라이딩한 상속 메소드
오버라이딩한
Object클래스의 메소드
클래스 멤버와 로컬 변수 사용
클래스 멤버 사용
클래스 멤버인 필드와 메소드를 제약없이 사용할 수 있다.
단,
this의 사용에 주의해야 한다.람다식 내부의
this는 바깥 객체가 아닌, 람다식에서 만든 익명 객체를 가리킨다.외부 객체의
this를 사용하고 싶다면,외부 객체명.this를 이용하면 된다.
중첩클래스를 생성하고 싶을 때는
상위인스턴스.new 중첩클래스명()과 같은 문법으로 생성하면 된다.
위 내용을 실행시켜보면 정상적으로 실행되는 것을 볼 수 있다.
로컬 변수 사용
람다식은 로컬 익명 구현 객체를 생성하는 것과 같다.
바깥 클래스 필드나 메소드는 위에서 살펴봤듯 제한없이 사용할 수 있다.
메소드의 매개변수 또는 로컬 변수는 일반 익명 구현 객체와 같이
final특성을 가져야 한다.그러므로 메소드 매개변수, 로컬 변수 등은 변경할 수 없다.
참조 링크
참조링크에 아주 잘 정리되어 있는데 핵심 골자는 내 생각에는 메소드에서 사용한 로컬 변수는 스택 메모리에 생성되고, 메소드가 끝나면서 회수당하기 때문이다. 만일, 해당 메소드가 끝나고도 존재하는 스레드를 람다로 구현했는데,
또한 스택에 있는 메모리는 스레드끼리 공유가 되지 않는다.
위와 같은 특성 때문에 애초에 람다에서는 로컬 지역 변수 참조가 불가능하다 그렇다면 도대체 왜 final로 된 로컬 지역 변수에는 접근이 가능할까? 그 이유는 바로 람다에서는 해당 지역 변수를 참조하는 것이 아닌 해당 지역 변수를 복사해서 사용하기 때문이다. 이와 같은 행위를 람다 캡처링이라고 한다.
예제 코드
이전의 UsingThis 클래스의 내용을 아래와 같이 살짝 바꿔보면 이해가 쉽다.
위의 경우에 메소드가 끝난 이후에도 thread는 계속 실행된다. 또한 실행되며 지역 변수인 localFieldVariable을 계속 참조한다. 하지만 실제 localFieldVariable은 이미 캡쳐링된 값이며, 실제 메소드에서 사용하던 지역 변수는 메소드가 끝나며 스택 메모리에서 반환된지 오래일 것이다.
표준 API의 함수적 인터페이스
자바 8부터
java.util.function표준 API 패키지에는 자주 사용되는 함수적 인터페이스를 제공한다.메소드에 이 함수적 인터페이스를 매개타입으로 사용하면 의도를 알기 좋다.
Consumer
매개값: O, 리턴값: X오직 값을 소비하기 위해 사용됨
내부 메소드인
.accept()를 통해 실행됨
위와 같은 형식으로 사용할 수 있으며, LongConsumer, DoubleConsumer, ObjDoubleConsumer<T>, ObjIntConsumer<T> 등 오브젝트와 숫자 타입에 관한 Consumer는 미리 정의되어 있는 것도 꽤 있다. 그런데 가독성과 통일성 측면에서 봤을 때 그냥 Consumer<T>와 BiConsumer<T, U>를 사용하지 않을 이유는 모르겠다.
Supplier
매개값: X, 리턴값: O오직 값을 생성하기 위해 사용된다.
내부 메소드인
.get()혹은 타입에 따라 미리 정의된.getXXX()메소드를 통해 실행된다.
위는 0~9까지의 수를 랜덤으로 출력하는 예제이다. IntSupplier와 같이 제네릭이 아닌 타입이 앞에 붙은 Supplier들도 존재한다.
Function
매개값: O, 리턴값: O일반적으로 매개 값과 리턴 값의 타입이 다름
주로 매개 값을 리턴 값으로 매핑하는 경우 사용한다.
내부 메소드인
.apply()혹은 타입에 따라 정의된.applyXXX()메소드를 통해 실행된다.
위는 중학생에 대한 정보에 고등학교 정보를 추가하여 고등학생으로 만드는 코드를 작성해본 것이다. 고등학교는 4가지 중에 아무거나 랜덤 배정된다.
위는 단순히 BiFunction 형태로 바꾸어본 것이다.
Operator
매개값: O, 리턴값: O일반적으로 매개 값과 리턴 값의 타입이 같음
주로 매개 값을 이용한 연산을 하고 결과를 리턴한다.
Function과 동일하게.apply()혹은.applyXXX()메소드를 통해 실행된다.매개값과 리턴값이 전부 있어서 그런 것 같다. 단, 연산 수행 후 동일한 타입으로 다시 리턴하는 경우 많이 쓰인다.
Operator는 예외적으로 Operator 자체 인터페이스는 존재하지 않고, BinaryOperator<T>, UnaryOperator<T>로 나뉜다. 같은 타입을 리턴하기 때문에 BinaryOperator의 경우에도 제네릭 타입은 하나만 받는다.
Predicate
매개값: O, 리턴값: O리턴 값은 오직
boolean타입
매개값을 조사하여
true/false를 반환한다..test()혹은.testXXX()메소드를 통하여 동작한다.2개의 요소를 쓸 때는 다른 함수적 인터페이스들과 같이
BiPredicate를 사용하면 된다.
Student라는 객체를 만들고, 점수를 부여하여 시험에 합격했는지 알아보는 과정을 Predicate 함수적 인터페이스를 통해 작성해보았다.
Consumer, Function, Operator 함수적 인터페이스의 andThen()과 compose() 디폴트 메소드
추상 메소드가 1개라면 함수적 인터페이스다.
디폴트 및 정적 메소드가 몇개라도 상관 없다.
위와 같은 관점에서 자바 표준 API의 함수적 인터페이스도 몇가지 정적 메소드를 갖고 있다.
.andThen().compose()
위 두개의 메소드는 첫번째 처리 결과를 두번째 매개값으로 제공해서 최종 결과값을 얻을 때 사용한다.

Consumer,Function,Operator가 제공하는 함수적 인터페이스 중 부분적인 것들에서만 사용 가능하다.
Function의 순차적 연결
Function은 함수적 인터페이스의 결과로 다른 타입을 반환했다. 연결되는 함수적 인터페이스에서 또 그 타입을 다른 타입으로 변환시킬 수 있다.
위는 Member 객체의 멤버인 Address 객체에서 City 문자열만 빼오는 예제이다. .compose()의 경우에는 호출 순서만 역순으로 하면 .andThen()과 결과가 같다.
Predicate 함수적 인터페이스의 and(), or(), negate() 디폴트 메소드와 isEqual() 정적 메소드
메소드 이름과 같이 각각 논리 연산자 and, or, not에 해당한다고 보면 된다.
위와 같은 형식으로 테스트할 수 있다. .isEqualTo()는 추상 메소드가 아닌 정적 메소드임에 유의하자.
BinaryOperator 함수적 인터페이스의 minBy()와 maxBy()
BinaryOperator<T> minBy(Comparator<? super T> comparator)BinaryOperator<T> maxBy(Comparator<? super T> comparator)
컬렉션의 .sort() 메소드처럼 해당 타입의 Comparator를 구현하면 그에 따라 최소값 혹은 최대값을 구해준다.
예제
PersonalHundredMeterRecord 클래스
위와 같이 개인의 100미터 달리기 기록을 저장하는 객체가 있다고 가정하자. 각각 이름과 100미터 달리기 기록을 저장한다. 기록은 LocalTime 객체를 이용해서 저장한다.
Comparator의 상속을 받아서 .compare()를 구현하고 Comparable의 상속을 받아서 .compareTo()도 구현해놨다.
테스트 메인 클래스
위는 각각 선수들의 기록 객체를 만들고, personalRecords라는 배열 리스트에 기록을 넣어놓은 부분이다. BinaryOperator.minBy() 메소드를 이용해 두개의 기록을 넣으면, 둘 중 누가 더 빨리(min) 뛰었는지 알 수 있다. 메소드를 .maxBy()로 바꾸면 둘 중 누가 느리게 뛰었는지 알 수도 있다. .compareTo() 메소드는 클래스 단에서 구현한 것을 이용했다. Comparable 인터페이스를 상속하면, compareTo()를 오버라이드하여 구현할 수 있다.
위 클래스의 .compare()도 구현해 놨기 때문에 Collections.sort() 메소드를 통해 정렬도 가능하다.
결과는 위와 같이 잘 나온다. .toString()도 구현해놓아서 클래스의 내용이 잘 보인다.
메소드 참조
메소드를 참조해서 불필요한 매개변수를 제거하여 코드를 간결히 보여주는 것이 목적이다.
정적 메소드와 인스턴스 메소드 참조
매개변수의 메소드 참조
생성자 참조
Last updated